Lecture 02
January 23, 2026
| Uncertainty Type | Source | Example(s) |
|---|---|---|
| Aleatory uncertainty | Randomness | Dice rolls, Instrument imprecision |
| Epistemic uncertainty | Lack of knowledge | Climate sensitivity, Premier League champion |

If \(\mathcal{D}\) is a distribution with PDF \(f_\mathcal{D}(x)\), the cumulative density function (CDF) of \(\mathcal{D}\) is \(F_\mathcal{D}(x)\):
\[F_\mathcal{D}(x) = \int_{-\infty}^x f_\mathcal{D}(u)du.\]
The quantile function is the inverse of the CDF:
\[q(\alpha) = F^{-1}_\mathcal{D}(\alpha)\]
So \[x_0 = q(\alpha) \iff \mathbb{P}_\mathcal{D}(X < x_0) = \alpha.\]
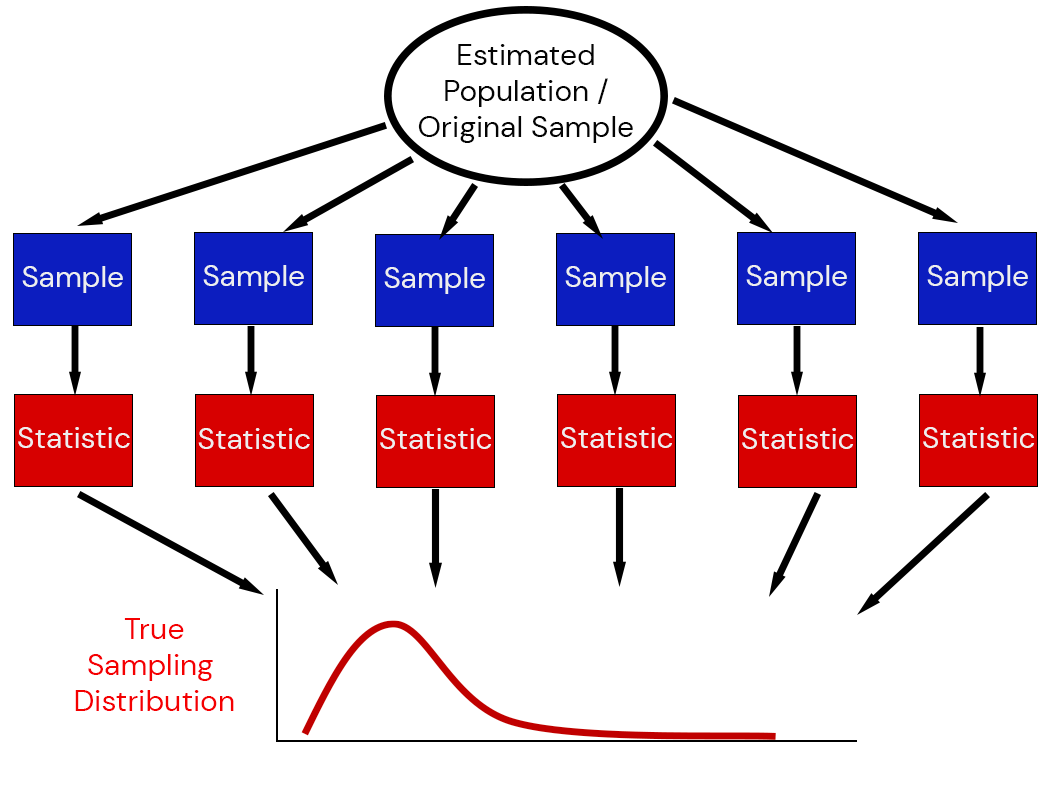
Illustration of the Sampling Distribution
\[f_\mathcal{D}(x) = p(x | \mu, \sigma) = \frac{1}{\sigma\sqrt{2\pi}} \exp\left(-\frac{1}{2}\left(\frac{x - \mu}{\sigma}^2\right)\right)\]


| Distribution | Likelihood |
|---|---|
| \(N(0, 1)\) | 3.7e-11 |

| Distribution | Likelihood |
|---|---|
| \(N(0, 1)\) | 3.7e-11 |
| \(N(-1, 2)\) | 5.9e-10 |

| Distribution | Likelihood |
|---|---|
| \(N(0, 1)\) | 3.7e-11 |
| \(N(-1, 2)\) | 5.9e-10 |
| \(N(-1, 1)\) | 1.2e-13 |
Likelihoods get very small very fast due to multiplying small numbers.
This is a computational problem due to underflow.
We use logarithms to avoid these issues: compute \(\log \mathcal{L}(\theta | x)\).