Are high water levels influenced by environmental change?
Does some environmental condition have an effect on water quality/etc?
Does a drug or treatment have some effect?
Each of these is a hypothesis about causation or influence.
Null Hypothesis Significance Testing
Check if the data is consistent with a “null” model;
If the data is unlikely from the null model (to some level of significance), this is evidence for the alternative.
If the data is consistent with the null, there is no need for an alternative hypothesis.
Alternative Hypothesis Meme
p-Values: Quantification of “Surprise”
One-Tailed Test:
Figure 1: Illustration of a p-value
Two-Tailed Test:
Figure 2: Illustration of a two-tailed p-value
Statistical Significance
Error Types
Null Hypothesis Is
True
False
Decision About Null Hypothesis
Don’t reject
True negative (probability \(1-\alpha\))
Type II error (probability \(\beta\))
Reject
Type I Error (probability \(\alpha\))
True positive (probability \(1-\beta\))
Navigating Type I and II Errors
The standard null hypothesis significance framework is based on balancing the chance of making Type I (false positive) and Type II (false negative) errors.
Idea: Set a significance level \(\alpha\) which is an “acceptable” probability of making a Type I error.
Aside: The probability \(1-\beta\) of correctly rejecting \(H_0\) is the power.
p-Value and Significance
Common practice: If the p-value is sufficiently small (below \(\alpha\)), reject the null hypothesis with \(1-\alpha\) confidence, or declare that the alternative hypothesis is statistically significant at the \(1-\alpha\) level.
This can mean:
The null hypothesis is not true for that data-generating process;
The null hypothesis is true but the data is an outlying sample.
What p-Values Are Not
Probability that the null hypothesis is true (this is never computed);
An indication of the effect size (or the stakes of that effect).
The null sampling distribution of \(S\) is \(N(0, \sqrt{\text{Var}(S)})\), where \[\text{Var}(S) = \frac{n(n-1)(2n+5)}{18} - \sum_{i=1}^g t_i(t_i - 1)(2t_i + 5),\]
\(g\) are the number of equal values and \(t_i\) is the size of tie group \(i\)
SF Tide Gauge Data: \(Var(S) = 224875\)
Difference in \(p\)-Values
Is there a trend in the SF tide gauge trend data?
Trend as regression (\(p\text{-value} \approx 0.01\))
Mann-Kendall test for monotonic trend (\(p\text{-value} \approx 0.03\))
If you conduct multiple statistical tests, you must account for all of these in the p-value computation and assessment of significance.
Multiple Comparisons Meme
Multiple Comparisons
For example: an appropriate applied test at a 5% significance level will result in a 5% Type I error rate. But if you do 100 independent tests, the Type I rate is 99.4%!
Multiple Comparisons Meme
Results Are Flashy, But Meaningless Without Methods
Elton John Results Section Meme
Source: Richard McElreath
Note: This Does Not Mean Null Hypothesis Testing Is Useless!
Examining and testing the implications of competing models is important, including “null” models!
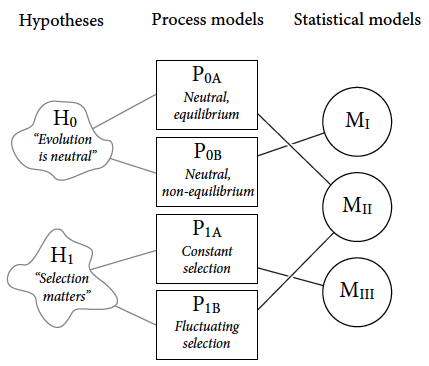
Null Hypothesis Selection Good Vs. Bad
What Can We Do Instead?
Use computing for simulation:
Develop sampling distributions and confidence intervals for more arbitrary models which reflect meaningful hypotheses about data-generating processes;
Compare model predictive performance involving models chosen based on scientific hypotheses.
When desired, compute \(p\)-values (including for multiple comparisons) by simulating Type I error rates.
Key Points
Hypothesis Testing
Classical framework: Compare a null hypothesis (no effect) to an alternative (some effect)
\(p\)-value: probability (under \(H_0\)) of more extreme test statistic than observed.
“Significant” if \(p\)-value is below a significance level reflecting acceptable Type I error rate.
Problems with NHST framework
Real “null” hypotheses are often more nuanced than in typical tests (which were often developed for controlled experiments or for computational convenience).
Decisions are often not binary (“significant/not significant”).
\(p\)-values are often over-interpreted and are often be incorrectly calculated, with negative outcomes!
Important: “Big” data can make things worse, as NHST is highly sensitive to small but evidence effects.
Upcoming Schedule
Next Classes
Wednesday: Introduction to Simulation and Random Sampling