Code
1×20 adjoint(::Vector{Bool}) with eltype Bool:
1 1 0 0 0 1 0 0 0 1 1 1 1 1 1 0 1 1 1 1Lecture 28
April 8, 2026
The sampling distribution of a statistic captures the uncertainty associated with random samples.
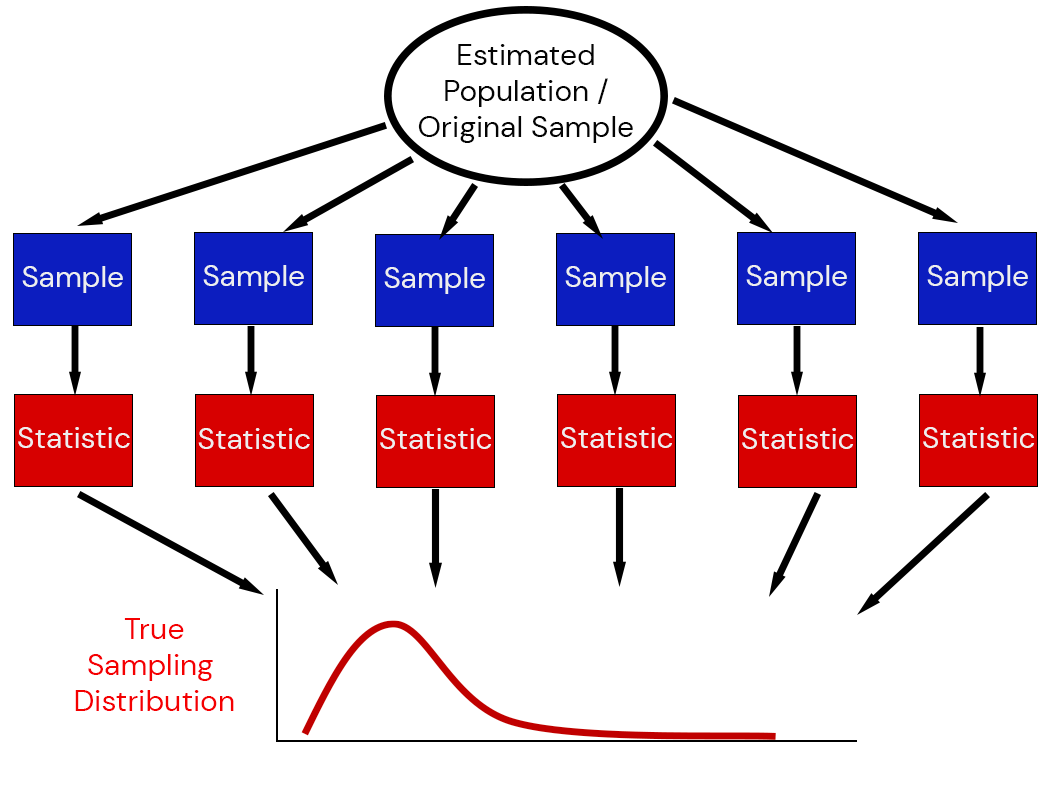
Efron (1979) suggested combining estimation with simulation: the bootstrap.
Key idea: use the data to simulate a data-generating mechanism.

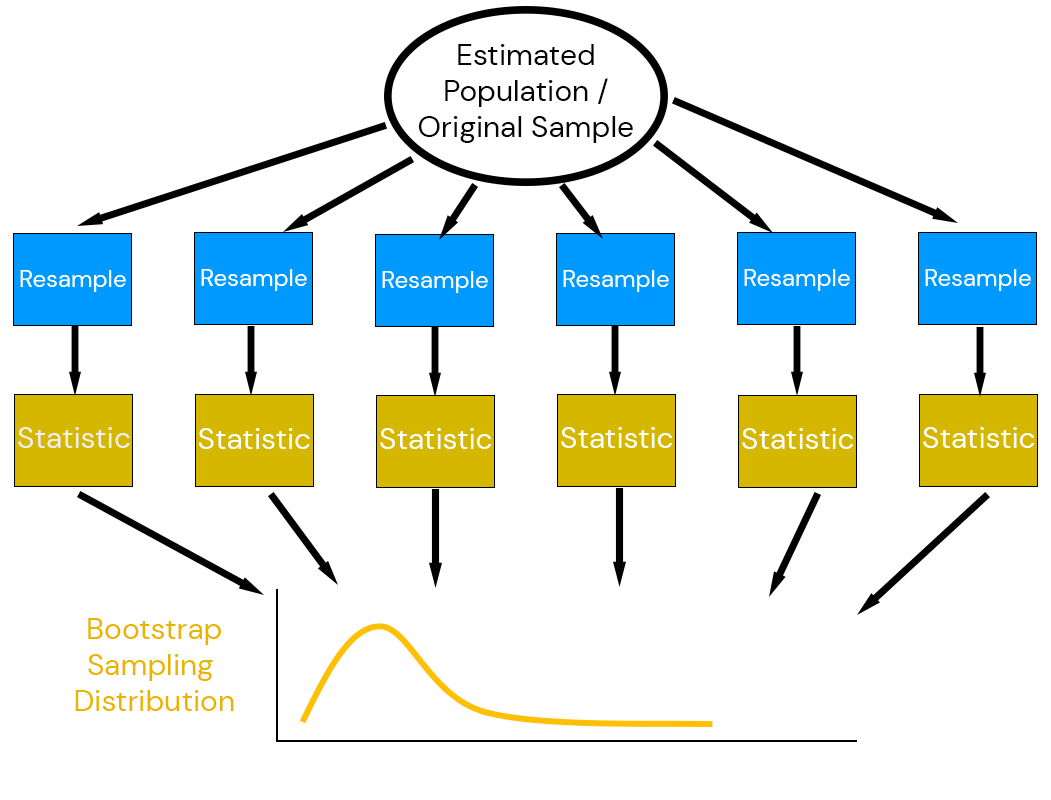
The non-parametric bootstrap is the most “naive” approach to the bootstrap: resample-then-estimate.
# bootstrap: draw new samples
function coin_boot_sample(dat)
boot_sample = sample(dat, length(dat); replace=true)
return boot_sample
end
function coin_boot_freq(dat, nsamp)
boot_freq = [sum(coin_boot_sample(dat)) for _ in 1:nsamp]
return boot_freq / length(dat)
end
boot_out = coin_boot_freq(dat, 1000)
q_boot = 2 * freq_dat .- quantile(boot_out, [0.975, 0.025])
p = histogram(boot_out, xlabel="Heads Frequency", ylabel="Count", title="1000 Bootstrap Samples", label=false, right_margin=5mm)
vline!(p, [p_true], linewidth=3, color=:orange, linestyle=:dash, label="True Probability")
vline!(p, [mean(boot_out) ], linewidth=3, color=:red, linestyle=:dash, label="Bootstrap Mean")
vline!(p, [freq_dat], linewidth=3, color=:purple, linestyle=:dot, label="Observed Frequency")
vspan!(p, q_boot, linecolor=:grey, fillcolor=:grey, alpha=0.3, fillalpha=0.3, label="95% CI")
plot!(p, size=(1000, 450))
Figure 1: Bootstrap heads frequencies for 20 resamples.
n_flips = 50
dat = rand(coin_dist, n_flips)
freq_dat = sum(dat) / length(dat)
boot_out = coin_boot_freq(dat, 1000)
q_boot = 2 * freq_dat .- quantile(boot_out, [0.975, 0.025])
p = histogram(boot_out, xlabel="Heads Frequency", ylabel="Count", title="1000 Bootstrap Samples", titlefontsize=20, guidefontsize=18, tickfontsize=16, legendfontsize=16, label=false, bottom_margin=7mm, left_margin=5mm, right_margin=5mm)
vline!(p, [p_true], linewidth=3, color=:orange, linestyle=:dash, label="True Probability")
vline!(p, [mean(boot_out) ], linewidth=3, color=:red, linestyle=:dash, label="Bootstrap Mean")
vline!(p, [freq_dat], linewidth=3, color=:purple, linestyle=:dot, label="Observed Frequency")
vspan!(p, q_boot, linecolor=:grey, fillcolor=:grey, alpha=0.3, fillalpha=0.3, label="95% CI")
plot!(p, size=(1000, 450))
Figure 2: Bootstrap heads frequencies for 1000 resamples.