Mixture model: several different distributions mixed with different weights.
\[\begin{aligned}
Z &\sim \text{Mult}(\pi_1, \ldots, \pi_K) \\
Y | Z &\sim \mathcal{D}_Z = f_Z
\end{aligned}\]
Very common to use Gaussians for \(\mathcal{D}_k\) but this isn’t necessary.
Mixture Models and Clustering
Mixture models are common for model-based clustering (a parametric alternative to e.g. \(k\)-means).
This is:
Good! A mixture model is predictive, might explain the data, and can be checked with e.g. cross-validation.
Bad! Highly sensitive to specification of distributions.
E-M Algorithm
Iterative optimization algorithm which alternates between computing the expected log-likelihood given parameter guesses (E-Step) and maximizing that expected log-likelihood to update parameter values (M-Step).
Can directly compute E-Step and M-Step outcomes with Gaussian mixtures.
Otherwise, can use numerical optimization for M-Step and Monte Carlo/other methods for E-Step.
What Don’t Mixture Models Tell Us
Mixture models are useful for clustering or generating bimodel distributions. But they are limited for understanding intertemporal dynamics.
For example: we don’t see the persistence of wet/dry states, with frequent switches between them. Is this reasonable?
To address this, we’ll need a generative model for state switching: a Hidden Markov Model.
Markov Chains
Hidden Markov Models
Instead, we might want to model the process that gives rise to a mixture distribution.
One way to do this for time series is with a Hidden Markov Model where the generative model at time \(t\) probability model “switches” probabilistically based on a Markov chain.
What Is A Markov Chain?
Consider a stochastic process \(\{X_t\}_{t \in \mathcal{T}}\), where
\(X_t \in \mathcal{S}\) is the state at time \(t\), and
\(\mathcal{T}\) is a time-index set (can be discrete or continuous)
\(\mathbb{P}(s_i \to s_j) = p_{ij}\).
Markov State Space
Markovian Property
This stochastic process is a Markov chain if it satisfies the Markovian (or memoryless) property: \[\begin{align*}
\mathbb{P}(X_{T+1} = s_i &| X_1=x_1, \ldots, X_T=x_T) = \\ &\qquad\mathbb{P}(X_{T+1} = s_i| X_T=x_T)
\end{align*}
\]
Example: “Drunkard’s Walk”
:img Random Walk, 80%
How can we model the unconditional probability \(\mathbb{P}(X_T = s_i)\)?
How about the conditional probability \(\mathbb{P}(X_T = s_i | X_{T-1} = x_{T-1})\)?
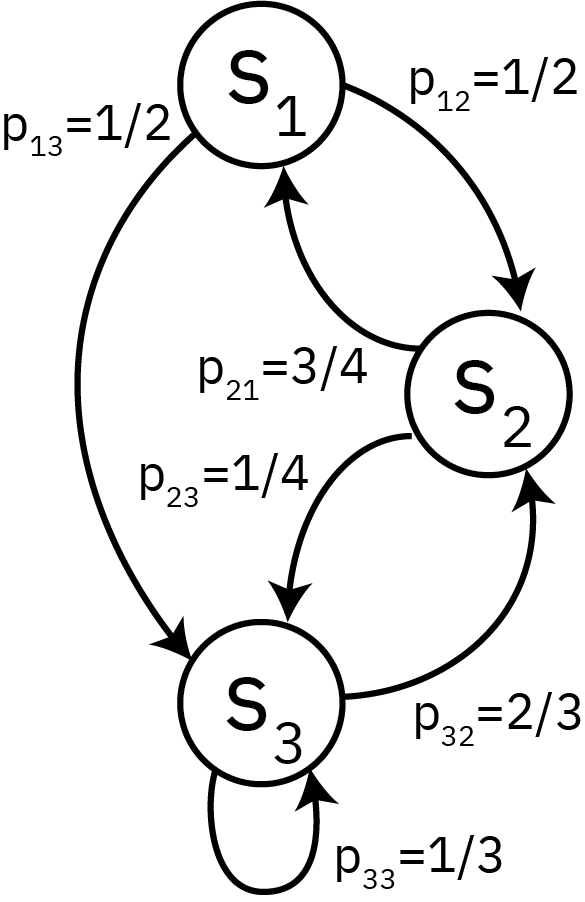
Example: Weather
Suppose the weather can be foggy, sunny, or rainy.
Based on past experience, we know that:
There are never two sunny days in a row;
Even chance of two foggy or two rainy days in a row;
A sunny day occurs 1/4 of the time after a foggy or rainy day.
Aside: Higher Order Markov Chains
Suppose that today’s weather depends on the prior two days.
Can we write this as a Markov chain?
What are the states?
Weather Transition Matrix
We can summarize these probabilities in a transition matrix\(P\): \[
P =
\begin{array}{cc}
\begin{array}{ccc}
\phantom{i}\color{red}{F}\phantom{i} & \phantom{i}\color{red}{S}\phantom{i} & \phantom{i}\color{red}{R}\phantom{i}
\end{array}
\\
\begin{pmatrix}
1/2 & 1/4 & 1/4 \\
1/2 & 0 & 1/2 \\
1/4 & 1/4 & 1/2
\end{pmatrix}
&
\begin{array}{ccc}
\color{red}F \\ \color{red}S \\ \color{red}R
\end{array}
\end{array}
\]
Rows are the current state, columns are the next step, so \(\sum_i p_{ij} = 1\).
Weather Example: State Probabilities
Denote by \(\lambda^t\) a probability distribution over the states at time \(t\).